上篇文章介绍了Prometheus Server自身的高可用方案,但除了Prometheus Server外,Alertmanager 也是整个告警体系里面重要的组件。所有的告警都需要通过它来进行发送,当Alertmanager出现问题时,告警信息将无法送达用户。
本文我们将讲解关于Alertmanager的集群方案。
一. 功能概述
Alertmanager使用 HashiCorp 公司的 Memberlist 库来实现集群功能。Memberlist 使用Go语言开发,并基于Gossip的协议来管理集群成员和成员故障检测。 Gossip协议(Gossip protocol)是一种去中心化、容错并保证最终一致性的协议,被广泛应用于分布式系统中。
Gossip的原理是由网络中的某个节点,通过一种随机的方式向集群中的N个节点同步信息,相关节点在收到消息后,又会重复相同的工作,最终达到整个集群所有节点的统一。
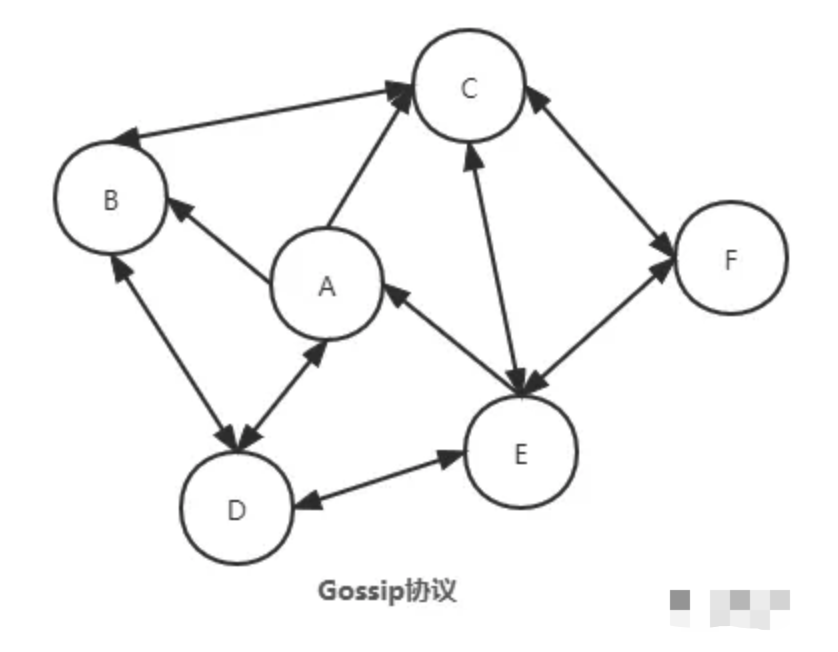
Gossip协议具有以下优点:
- 扩展性强,可以允许集群内节点任意增加或者减少。
- 协议操作简单,实现起来简单方便。
- 容错性强,节点之间是平等关系,任何节点出现问题都不影响集群。
- 最终一致性,可以在较短时间内快速将变化覆盖到全局节点。
二. Alertmanager配置
在本次配置中,我们通过三个Alertmanager来进行演示,分别为am1、am2和am3,其中am1主机做为集群的启动节点。每台alertmanager必须保证配置文件的一致性,否则集群实际上并不是高可用的效果。
am1: 192.168.214.100
am2: 192.168.214.108
am3: 192.168.214.109Gossip的传播需要指定特定端口,此处我们使用8001为监听端口。为了能够让Alertmanager节点之间进行通讯,需要在Alertmanager启动时设置相应的参数。其中主要的参数包括:
- --cluster.listen-address string: 当前实例集群服务监听地址
- --cluster.peer value: 初始化时关联的其它实例的集群服务地址
am1启动配置: $ alertmanager --config.file alertmanager.yml --storage.path /data/alertmanager/ --cluster.listen-address="192.168.214.100:8001" &
am2与am3启动配置: alertmanager --config.file alertmanager.yml --storage.path /data/alertmanager/ --cluster.listen-address="0.0.0.0:8001" --cluster.peer=192.168.214.100:8001 &
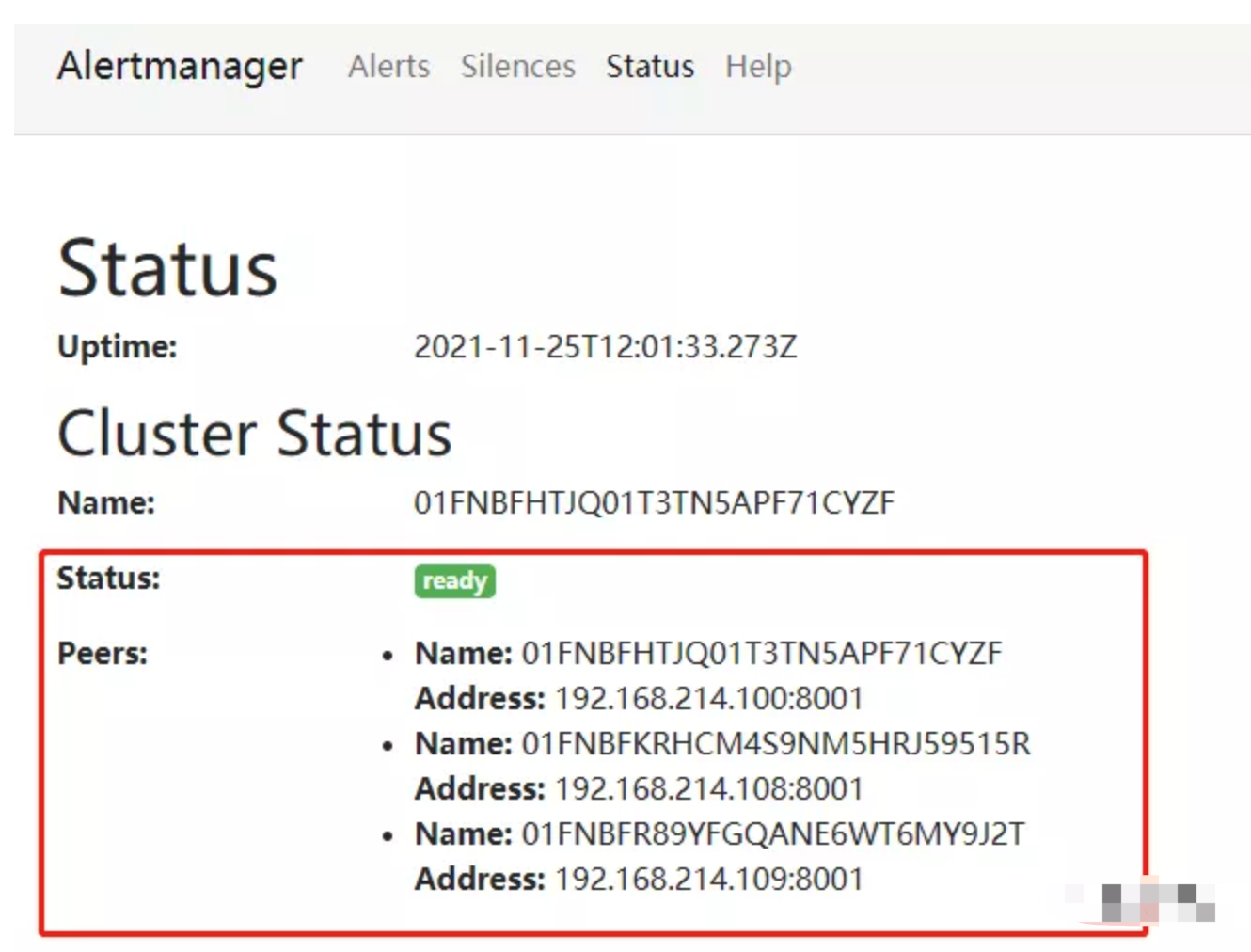
在配置完成后,我们可以在任意一个Alertmanager中看到如下状态,证明三个节点已加入到集群中。
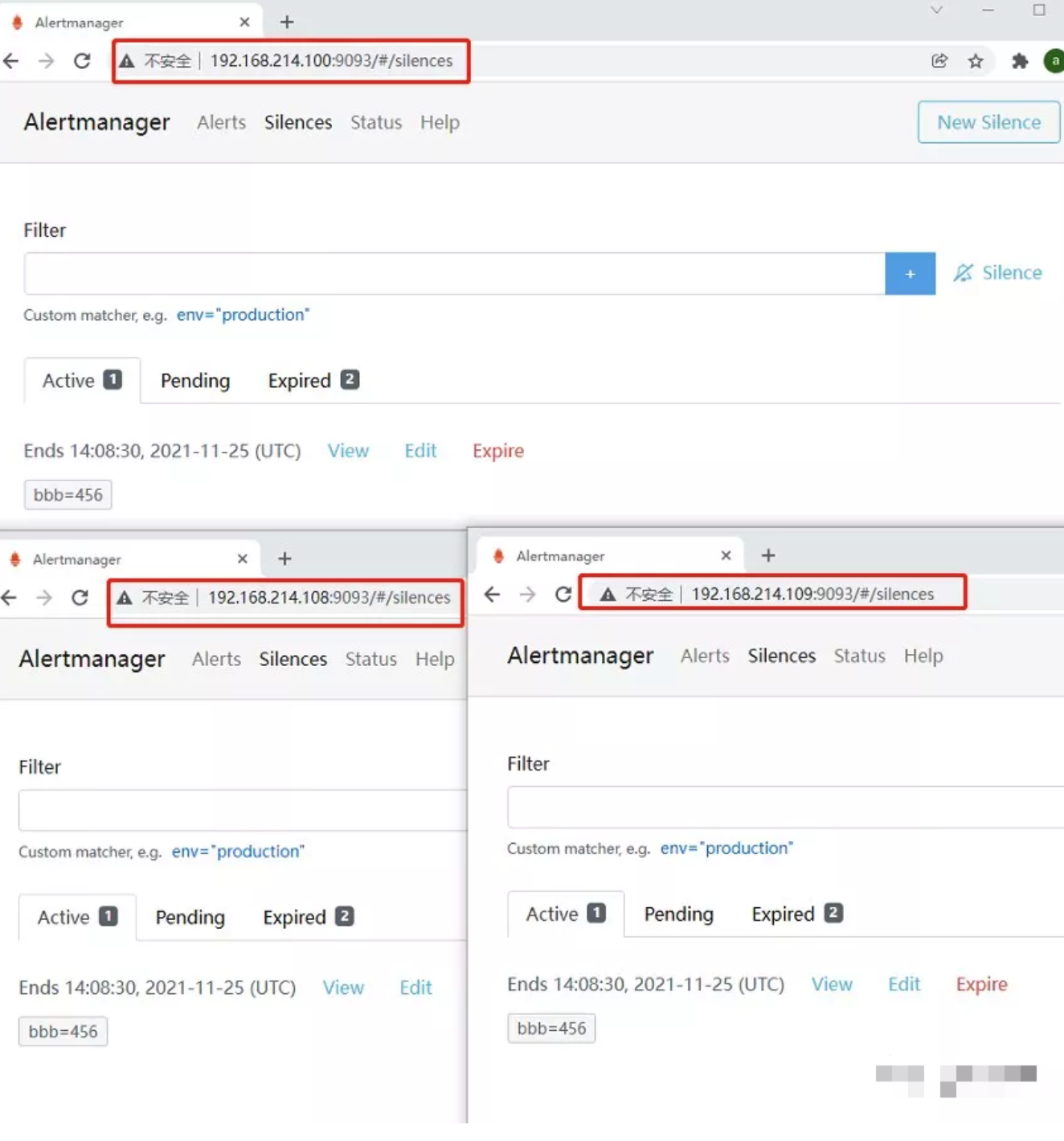
在集群启动后,我们可以在其中一个Alertmanager上设置silence,并查看配置是否复制到其他Alertmanager节点,以此来验证集群是否正常工作。如下图所示,现在集群已经在正常运行,接下来可以开始进行Prometheus的设置。
三.Prometheus设置
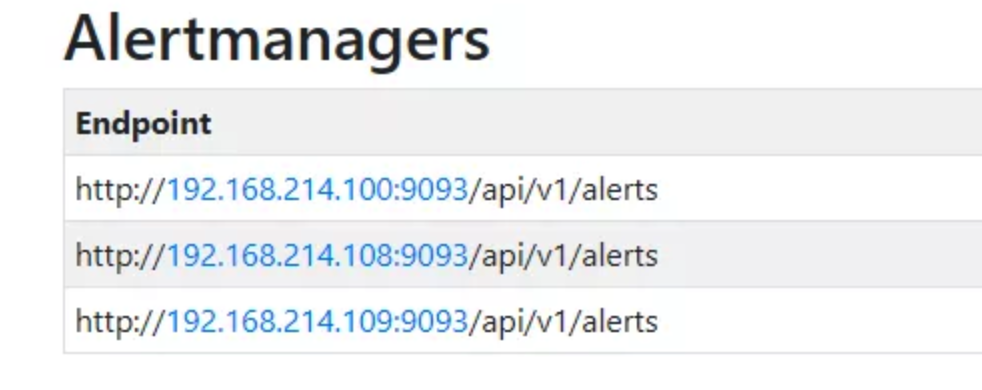
对于Alertmanager集群,我们不需要在集群前面额外增加负载均衡器。在Prometheus的配置文件中,只需要将所有Alertmanager的地址配置进去,这样当集群中的某个Alertmanager发生故障时,Prometheus会自动找寻另一个来发送警报。而收到警报Alertmanager节点,自身会负责与集群中的其他活动成员共享所有收到的警报。
alerting:
alertmanagers:
- static_configs:
- targets:
- '192.168.214.100:9093'
- '192.168.214.108:9093'
- '192.168.214.109:9093'启动Prometheus后,我们在Status页面会看到相关的Alertmanager信息,代表配置成功。